paddu.bits
May 12, 2022, 7:02am
#1
Hi Everyone,
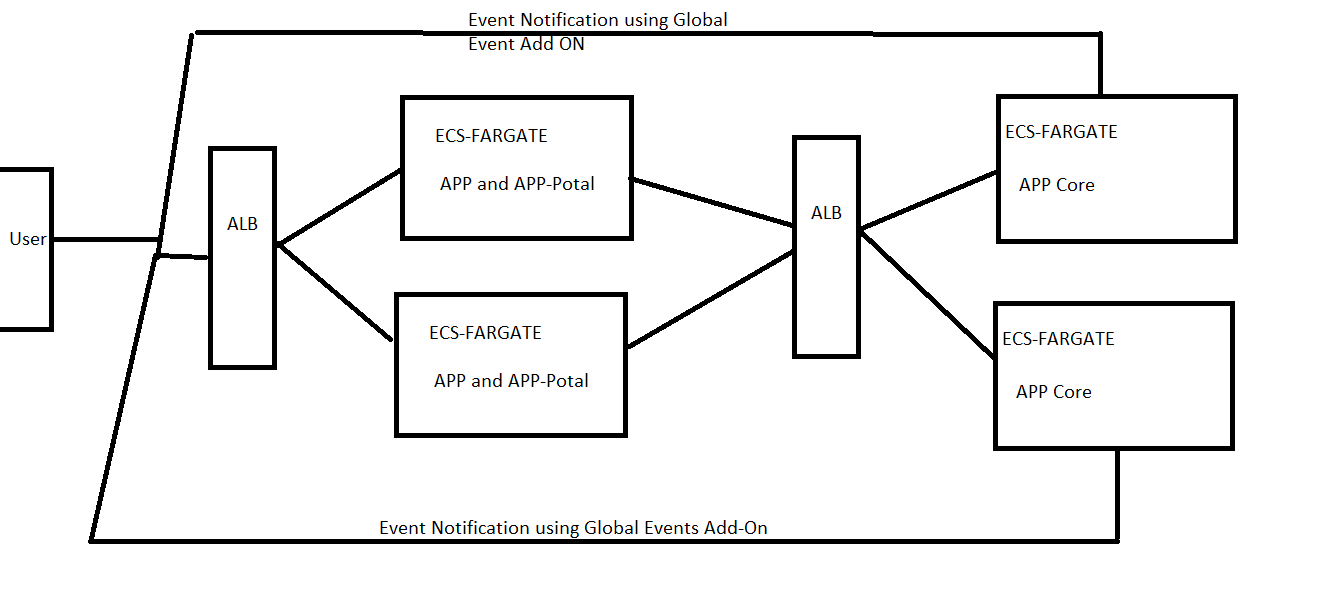
We are currently running our CUBA application in an EC2 but now we are trying to scale our application. Below is the snapshot of the deployment we are planning
we want to ensure the User Session information is consistent across all the instances. we are planning for S3 storage for files.
Thank you in advance for the support.
albudarov
May 13, 2022, 7:30am
#2
Hi,
To use Amazon S3 for file storage, you need to add the addon to your project:AWS Filestorage – CUBA Platform
For User Session synchronization (and other middleware caches synchronization) you need to configure JGroups cluster.Configuring Interaction between Middleware Servers - CUBA Platform. Developer’s Manual
Note that most likely built-in jgroups.xml (UDP-based config) will not work in AWS network.
So recommended configurations are:
Personally I have used JDBC_PING for AWS cluster deployment.
paddu.bits
August 13, 2022, 2:06am
#4
Hi Alexander,
Could you please share the jgroups xml with jdbc_ping that you have used in AWS for my reference?
Thank you.
albudarov
August 19, 2022, 4:36pm
#5
(this is an Ansible template for the file)
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups.xsd">
<!-- TCP based stack -->
<TCP bind_port="7800"
bind_addr="{{ myhostname }}"
recv_buf_size="${tcp.recv_buf_size:5M}"
send_buf_size="${tcp.send_buf_size:5M}"
max_bundle_size="64K"
sock_conn_timeout="300"
thread_pool.min_threads="2"
thread_pool.max_threads="8"
thread_pool.keep_alive_time="5000"/>
<JDBC_PING async_discovery="true"
connection_url="jdbc:postgresql://{{ db_host }}/{{ db_name }}"
connection_driver="org.postgresql.Driver"
connection_username="{{ db_user }}"
connection_password="{{ db_password }}"
initialize_sql="create table if not exists JGROUPSPING (
own_addr varchar(200) not null,
cluster_name varchar(200) not null,
ping_data bytea,
primary key (own_addr, cluster_name))"/>
<MERGE3 min_interval="10000"
max_interval="30000"/>
<FD_SOCK client_bind_port="50100"
start_port="50000"
port_range="0"/>
<FD timeout="3000"
max_tries="3"/>
<VERIFY_SUSPECT timeout="1500"/>
<BARRIER/>
<pbcast.NAKACK2 use_mcast_xmit="false"
discard_delivered_msgs="true"/>
<UNICAST3/>
<pbcast.STABLE stability_delay="1000"
desired_avg_gossip="50000"
max_bytes="4M"/>
<pbcast.GMS print_local_addr="true"
join_timeout="2000"
view_bundling="true"/>
<MFC max_credits="2M"
min_threshold="0.4"/>
<FRAG2 frag_size="60K"/>
<RSVP resend_interval="2000"
timeout="10000"/>
<pbcast.STATE_TRANSFER/>
</config>